Atomic-level
Atomic-level data quality focuses on identifying problems inherent in your raw data, irrespective of specific analytics use cases. For example, invalid ICD-10-CM diagnosis codes are an atomic-level data quality problem. Obviously invalid codes like this will also impact analytics use cases, but at the atomic-level we focus on identifying and summarizing these problems across the dataset without linking them to specific analytics use cases.
There are two types of atomic-level data quality problems:
- Mapping Problems
- Inherent Problems
Mapping problems are data quality problems that are inadvertently introduced when data is transformed from the source to the Tuva Data Model. These problems can be corrected by fixing the mapping.
Inherent problems are data quality problems that are artifacts of the raw data that were not introduced during mapping and cannot be corrected by mapping. They can only be corrected by acquiring better data from the source.
For each claims data table in the Tuva Input Layer, we analyze several domains of data quality problems. We have organized these domains in order of importance below. To view a union of all the individual checks (ignoring date trend and other checks that are more complex) query the table below:
select *
from data_quality.data_quality_test_summary
order by result_count desc
Medical Claim
Primary Key
The most basic check we perform on each data table is a primary key check. This ensures the data in the table is at the proper grain. Modern data warehouses (e.g. Snowflake) don't always enforce primary keys. If the primary key isn't set properly this could cause downstream queries to unintentionally explode in size and number of records.
The primary key on the medical_claim table is comprised of 3 fields: claim_id, claim_line_number, and data_source. The primary_key_check table verifies whether there are any duplicates across the primary key fields for each data table. If any result in the duplicate_records column is greater than zero, then that table's primary key is not set properly and this needs to be corrected in the mapping.
select *
from data_quality.primary_key_check
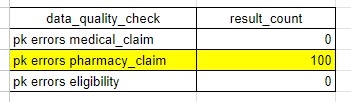
In the example above the pharmacy_claim table has 100 distinct claims that have multiple records with the same values for the primary key fields. If any result in this table is non-zero you need to correct the mapping to fix it.
Person ID
The patient is at the center of the vast majority of the analyses we're interested in. Therefore it's important that we check a few things related to the person_id field on every medical claim, specifically:
- Does every line on each claim have a value for
person_idpopulated? - Is there more than one value for
person_idwithin a single claim (there shouldn't be)? - Does the
person_idvalue indicated on the claim have corresponding valid eligibility during the time period when claim was rendered?
The medical_claim_person_id table verifies whether any of these data quality problems occur in the medical_claim table. You can query it as follows:
select *
from data_quality.medical_claim_person_id
This query returns the number of unique claim IDs that have each of these data quality problems.
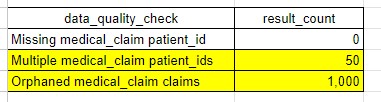
In the example table above we observe the following:
- person_id is populated for every single record in the medical_claim table
- 50 claim IDs have more than 1 person_id. This can occur when two or more distinct lines on the claim have different values for person_id.
- 1,000 claim IDs are considered "orphaned claims". This means that the claim_start_date or claim_end_date occur during a month when the patient does not have insurance eligibility.
If any of these problems occur in your data you should attempt to correct them in mapping. However the specific techniques to do this will vary by dataset and it may not be possible to correct the problems. If the problems can't be correct we still include these records in the dataset, but there will be limitations in terms of how useful they are for analytics.
Date Fields
The majority of analyses are longitudinal in nature, meaning they look at trends or changes over time. To make these sorts of analyses possible we need reliable date fields. In medical claims the following fields are the important date fields:
claim_start_dateclaim_end_dateclaim_line_start_dateclaim_line_end_dateadmission_datedischarge_datepaid_date
We need to check these fields for the following problems:
- Every claim line should have a value populated for the following fields:
claim_start_dateclaim_end_dateclaim_line_start_dateclaim_line_end_datepaid_date
-
Every institutional claim should have an
admission_dateanddischarge_datefield populated. -
The following fields should have 1 and only 1 value on the claim when they are populated.
claim_start_dateclaim_end_dateadmission_datedischarge_date
It's possible and expected for claim line dates to be different for different records on a single claim.
The following table returns the count of distinct claims that violate the rules outlined above.
select *
from data_quality.medical_claim_date_checks
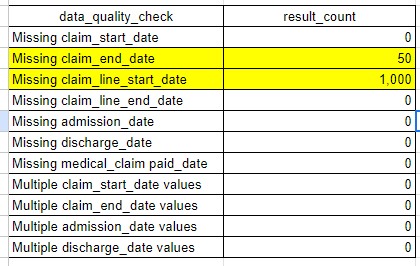
In the example table above we can see that 50 medical claims are missing a claim_end_date and 1,000 claims are missing a claim_line_start_date.
Beyond these basic date checks, we need to check whether the values within our date fields are reasonable over time. For example, if we have a dataset that covers 3 calendar years, it's possible that claim_start_date is perfectly normal for the first two years, but then is completely missing thereafter. The following query analyzes trends in each of the date fields by looking at the count of distinct claims over time for each date field:
select *
from data_quality.claim_date_trends
order by 1
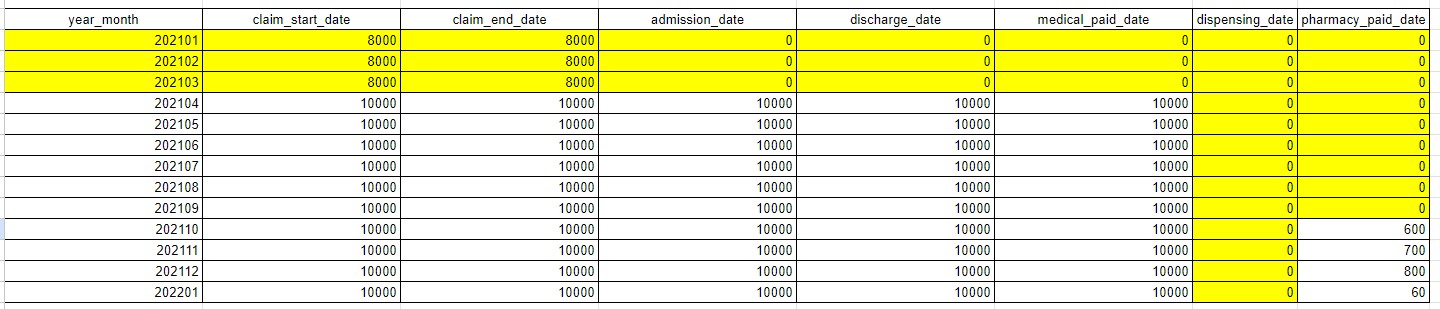
In the example table above we see that the first 3 months of 2021 have claim start and end dates populated, but no admission, discharge, or paid dates. This indicates we are missing date information on these fields during these months.
Diagnosis and Procedure Fields
Most analyses we perform incorporate information about the patient's health conditions and / or procedures performed on the patient. Therefore it's critical that we have solid information on the ICD-10-CM and ICD-10-PCS codes which encode this information.
Specifically we check to ensure the following:
- Every claim line should have a value populated for diagnosis_code_1
- Every value in the diagnosis_code_1 field should be a valid ICD-10-CM code
- Every claim should have 1 and only 1 value for diagnosis_code_1
- For any secondary diagnosis codes that are populated (e.g. diagnosis_code_2, diagnosis_code_3, etc.) these values should be valid ICD-10-CM codes
- We also want to know the percent of claims that have 1 or more secondary diagnosis codes
- For any procedure codes (e.g. procedure_code_1, procedure_code_2, etc.) that are populated these values should be valid ICD-10-PCS codes
The query below will display the results from each of these checks:
select *
from data_quality.dx_and_px
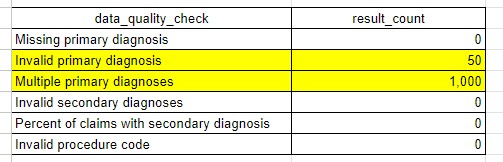
In the example table above, we see that 50 claims have 1 or more invalid primary diagnosis codes and that 1,000 claims have more than 1 primary diagnosis code, making it impossible to use the primary diagnosis code from these claims in analysis.
Institutional Header Fields
There are several key fields on institutional claims that we use to identify the type of service being delivered and to group claims into encounters. These fields include the following:
- bill_type_code
- discharge_disposition_code
- ms_drg_code
- apr_drg_code
For each of these fields we need to check institutional claims to ensure the following is true:
- Every claim line has a value populated
- The value populated is valid
- There is 1 and only 1 value for each claim across all claim lines
The following code returns the results of these checks:
select *
from data_quality.medical_claim_inst_header_fields
order by result_count desc
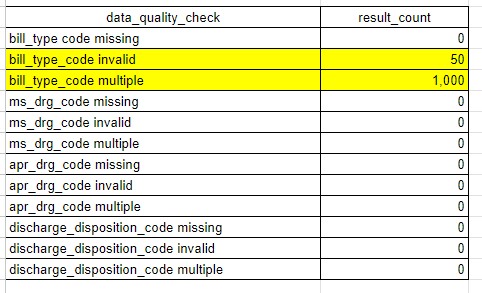
In the example output above we see that 50 claims have an invalid bill_type_code, meaning it does not match a code in the terminology table, and that 1,000 claims have multiple values for bill_type_code.
Claim Line Fields
There are a few key fields across both professional and institutional claims that we use to assign service categories and to group claims into encounters. These including the following fields:
- revenue_center_code
- place_of_service_code
- hcpcs_code
We need to check these fields to see if the values of these fields are missing or invalid. The following table returns the results of this.
select *
from data_quality.medical_claim_claim_line_fields
order by result_count desc

In the example table above we see that 1,000 claims are missing revenue_center_code.
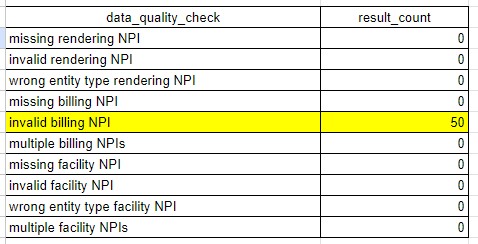
Provider NPI Fields
Often we wish to do analysis about the specific providers or facilities delivering care. NPI is critical here because it's how we identify providers, facilities, and health systemcs. Therefore we perform the following checks on NPI:
- Every claim should have 1 and only 1
billing_npiand it should be valid - Every claim should have 1 or more
rendering_npivalues and they should be valid - Every institutional claim should have 1 and only 1
facility_npiand it should be valid
select *
from data_quality.medical_claim_provider_npi
order by result_count desc
Trended Claim Volume and Dollars
Often we see anomalies where claim volume or dollars can change unexpectedly over time, possibly indicating a data quality problem. Therefore we need to check whether this is the case.
select *
from data_quality.medical_claim_volume_and_dollars
order by year_month
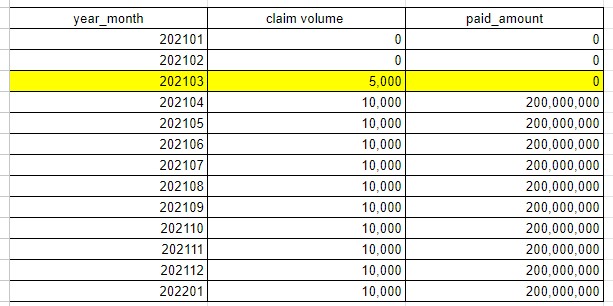
In the example above we clearly have medical claims in the month of March 2021 but we have no paid amounts.
Data Loss
Often when we map data we perform complex filtering and other types of transformation operations. In these scenarios it can be easy for unintended data loss to occur. Therefore we need to confirm some basic statistics between the raw source data and the Tuva Input Layer to ensure unintended data loss hasn't occurred.
The table identified in the query below will only populate once you've created the data loss table in the Input Layer. To create this table, you manually calculate the exact same metrics as the source data and map these results to the data_loss table in the claims Input Layer.
select *
from data_quality.data_loss
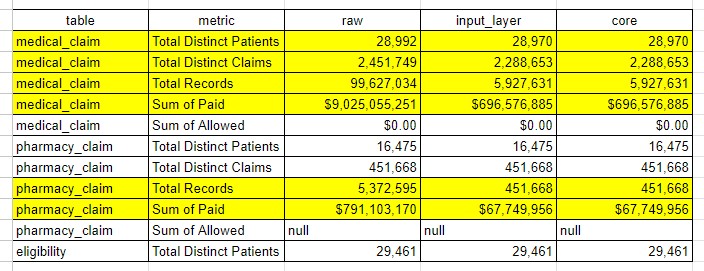
In the example above we can compare several basic "table stakes" statistics for medical and pharmacy claims, as well as eligibility. The highlighted rows all show data loss as we move from raw to input layer to core. Some of this data loss might be expected and explainable. You should work to understand any and all data loss that is not currently explainable before moving on.
Pharmacy Claim
Primary Key
The most basic check we perform on any table is a primary key check. This ensures the data in this table is at the proper grain. Modern data warehouses (e.g. Snowflake) don't always enforce primary keys. If the primary key isn't set properly this could cause downstream queries to explode in size and number of records.
The primary key on the pharmacy_claim table is comprised of 3 fields: claim_id, claim_line_number, and data_source. Query the following table to check whether your data has any duplicate records across these fields. The duplicate_records column in this table should equal 0 for every table. If it's not you have a primary key problem to fix.
select *
from data_quality.primary_keys
Person ID
Similar to the medical_claim table, the patient is at the center of the vast majority of the analyses we're interested in. Therefore it's important that we check a few things related to the person_id field on every pharmacy claim, specifically:
- Does every line on each claim have a value for
person_idpopulated? - Is there more than one value for
person_idwithin a single claim? - Does the
person_idvalue indicated on the claim have corresponding valid eligibility during the time period when claim was rendered?
The pharmacy_claim_person_id table verifies whether any of these data quality problems occur in the pharmacy_claim table. You can query it as follows:
select *
from data_quality.pharmacy_claim_person_id
This query returns a table with one row per check and the count of unique claim IDs that have that particular data quality issue
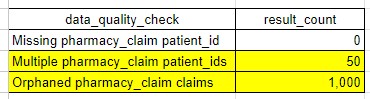
In the example table above we observe the following:
- person_id is populated for every single record in the pharmacy_claim table
- 50 claim IDs have more than 1 person_id. This can occur when two or more distinct lines on the claim have different values for person_id.
- 1,000 claim IDs are considered "orphaned claims". This means that the paid_date or the dispensing_date occurs during a month when the patient does not have insurance eligibility.
If any of these problems occur in your data you should attempt to correct them in mapping. However the specific techniques to do this will vary by dataset and it may not be possible to correct the problems. If the problems can't be correct we still include these records in the dataset, but there will be limitations in terms of how useful they are for analytics.
Date Fields
The majority of analyses are longitudinal in nature, meaning they look at trends or changes over time. To make these sorts of analyses possible we need reliable date fields. In pharmacy claims the following fields are the important date fields:
paid_datedispensing_date
We need to check these fields to ensure they are populated for every claim and claim line:
paid_datedispensing_date
The following table returns the count of distinct claims that violate the rules outlined above.
select *
from data_quality.pharmacy_claim_date_checks

In the example table above we can see that 1000 pharmacy claims are missing a dispensing_date while paid_date is always populated.
Beyond these basic date checks, we need to check whether the values within our date fields are reasonable over time. For example, if we have a dataset that covers 3 calendar years, it's possible that paid_date is perfectly normal for the first two years, but then is completely missing thereafter. The following query analyzes trends in each of the date fields by looking at the count of distinct claims over time for each date field:
select *
from data_quality.claim_date_trends
order by 1
In the example table above we see that the first 3 months of 2021 have some small amount of claims with paid_dates. It is worth further investigation to see if we are missing dates for those claims, or if that is just ramp up in the pharmacy claims data we have received.
NDC
Every pharmacy claim should have an NDC (National Drug Code) on it. We check to see whether every claim and claim line has an NDC field that is populated, and whether that NDC is a valid NDC (meaning it is part of the published NDC list by the FDA). These checks are found here:
select *
from data_quality.pharmacy_claim_ndc
order by 1

Some invalid NDCs are expected, as there are often NDCs in pharmacy data for items like 'glucose test strips' that are not found on the FDA list.
Prescription Details
A pharmacy claim will have prescription details in these important fields:
quantitydays supplyrefills
We check each of these fields to ensure they are are populated.
select *
from data_quality.pharmacy_claim_prescription_details
order by 1
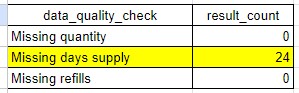
Quantity is the most important of the fields, as it is used in the pharmacy mart to calculate the generic available opportunity.
NPI Fields
Pharmacy claims contain two important NPI fields:
prescribing_npidispensing_npi
Of the two fields, prescribing npi is more important as it enables analysis around who is prescribing certain drugs and what type of practioners they are.
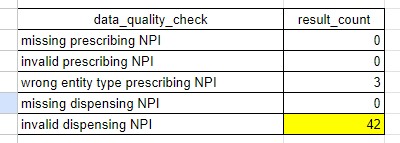
We check these fields to ensure they are populated and valid NPIs. We also check to ensure the prescribing_npi is the expected entity type (an individual instead of an organization).
select *
from data_quality.pharmacy_claim_npi
Trended Claim Volume and Dollars
Often we see anomalies where claim volume or dollars can change unexpectedly over time, possibly indicating a data quality problem. Therefore we need to check whether this is the case.
select *
from data_quality.pharmacy_claim_volume_and_dollars
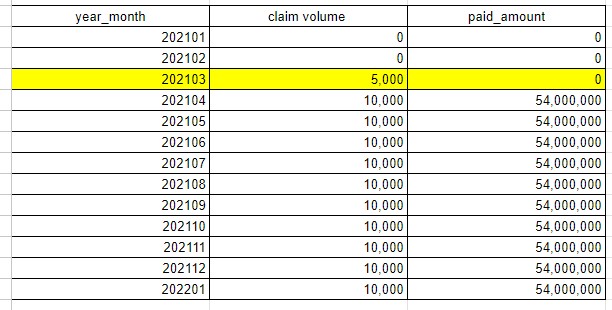
In the example above we clearly have pharmacy claims in the month of March 2021 but we have no paid amounts.
Data Loss
Often when we map data we perform complex filtering and other types of transformation operations. In these scenarios it can be easy for unintended data loss to occur. Therefore we need to confirm some basic statistics between the raw source data and the Tuva Input Layer to ensure unintended data loss hasn't occurred.
The table identified in the query below will only populate once you've created the data loss table in the Input Layer. To create this table, you manually calculate the exact same metrics as the source data and map these results to the data_loss table in the claims Input Layer.
select *
from data_quality.data_loss
In the example above we can compare several basic "table stakes" statistics for medical and pharmacy claims, as well as eligibility. The highlighted rows all show data loss as we move from raw to input layer to core. Some of this data loss might be expected and explainable. You should work to understand any and all data loss that is not currently explainable before moving on.
Eligibility
Primary Key
The most basic check we perform on any table is a primary key check. This ensures the data in this table is at the proper grain.
Modern data warehouses (e.g. Snowflake) don't always enforce primary keys. If the primary key isn't set properly this could cause
downstream queries to explode in size and number of records.
The primary key on the eligibility table is comprised of 4 fields: memner_id, payer, plan, enrollment_start_date, and enrollment_end_date.
Query the following table to check whether your data has any duplicate records across these fields. The duplicate_records
column in this table should equal 0 for every table. If it's not you have a primary key problem to fix.
select *
from data_quality.primary_key_check
In the example above the pharmacy_claim table has 100 distinct claims that have multiple records with the same values for the primary key fields. If any result in this table is non-zero you need to correct the mapping to fix it.
Person ID
Does every row of eligibility have a person_id populated?
The eligibility_missing_person_id table verifies whether any rows do not have a person_id. You can query it as follows:
select *
from data_quality.eligibility_missing_person_id
This query returns the number of rows in the eligibility table that do not have a person_id. If this number is greater than 0,
you need to correct the mapping to fix it.
![]()
In the example table above we observe that all rows in the source data have a person_id.
Date Fields
In eligibility, the following fields are the important date fields:
enrollment_start_dateenrollment_end_date
We need to check these fields for the following problems:
- Every row in the eligibility input layer should have valid dates in these fields.
enrollment_start_dateshould be less than or equal toenrollment_end_date.- The latest
enrollment_end_datevalue should be the last day of the current month when the tuva project was last run. - Dates should be relatively recent e.g., no dates before 1900.
The following table returns the count of eligibility rows that violate the rules outlined above.
select *
from data_quality.eligibility_date_checks

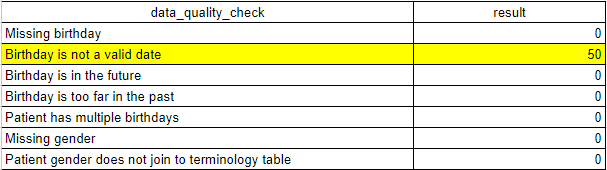
Patient Demographics
Birth date and gender information about a member is crucial for some downstream analytics. The eligibility_demographics
table provides a count of eligibility spans that are missing this data.
select *
from data_quality.eligibility_demographics
Payer Info
The eligibility_missing_payer table provides a count of eligibility spans that are missing the following:
- payer type (e.g. medicare, medicaid, commercial)
- payer name (e.g. CMS)
- invalid payer
select *
from data_quality.eligibility_missing_payer

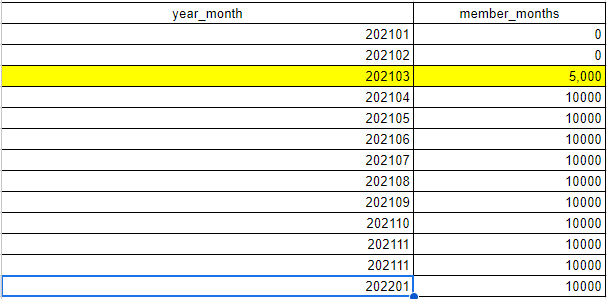
Trended Enrollment Volume
The eligibility_trend table provides a count of eligibility spans that contain enrollment in the corresponding year and month.
Trending this count can surface abnormal drops and/or spikes in enrollment.
select *
from data_quality.eligibility_trend
order by year_month
Data Loss
Often when we map data we perform complex filtering and other types of transformation operations. In these scenarios it can be easy for unintended data loss to occur. Therefore we need to confirm some basic statistics between the raw source data and the Tuva Input Layer to ensure unintended data loss hasn't occurred.
The table identified in the query below will only populate once you've created the data loss table in the Input Layer.
To create this table, you manually calculate the exact same metrics as the source data and map these results to the
data_loss table in the claims Input Layer.
select *
from data_quality.data_loss
In the example above we can compare several basic "table stakes" statistics for medical and pharmacy claims, as well as eligibility. The highlighted rows all show data loss as we move from raw to input layer to core. Some of this data loss might be expected and explainable. You should work to understand any and all data loss that is not currently explainable before moving on.