Metriport
Metriport offers clinical data from the largest health information networks in the country, via a single open-source API.
DataFlow
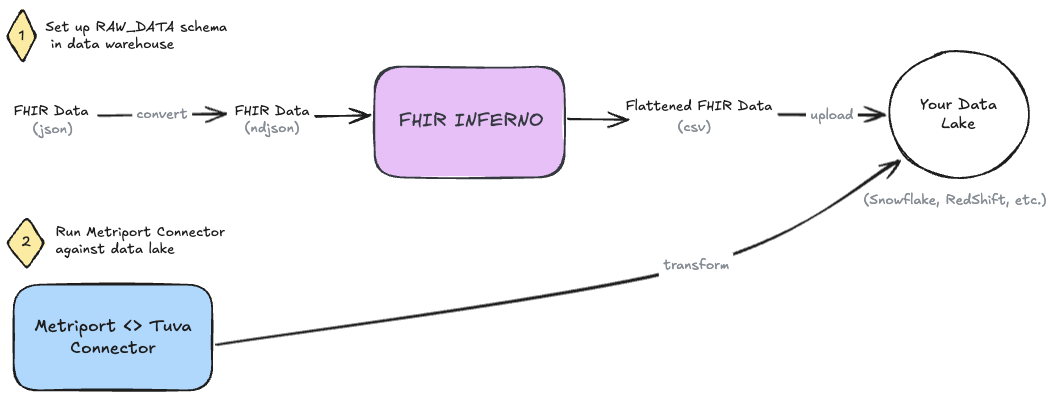
Instructions
Metriport provides clinical data in the FHIR R4 JSON format.
Step 0: Get FHIR data from Metriport
First things first, pull FHIR data from Metriport using whatever method you're comfortable.
- See Metriport's postman collection.
- See Metriport's API docs.
Save the file to only contain the Bundle.entry array.
Step 1: Convert FHIR JSON to NDJSON
First, we need to convert our FHIR json data to NDJSON. We recommend using the command line tool jq to do this - brew install it! Once it's installed, run the following command on the file, e.g. "metriport-fhir.json", in your terminal.
jq -c '.[]' metriport-fhir.json > output.ndjson
Step 2: Use FHIR Inferno to Flatten JSON and Prepare Data Tables
Clone the FHIR Inferno.
Use the helper-scripts/create_table_create_csv.py script to generate SQL scripts based on the Metriport Configs. We recommend naming your schema RAW_DATA, for consistency. Execute the resulting SQL scripts in your data warehouse to create resource-specific tables in this schema.
Next, use helper-scripts/parse_ndjson_bundle.py to transform the NDJSON into relational CSV tables and load those CSVs into the data tables created in the previous step, in correspondence to their resource type.
Step 3: Set up 'Metriport Connector'
Now clone the Metriport Connector (i.e. dbt project) to your local machine.
All of the configurations you will need to make will be in the dbt_project.yml file:
- set the
input_databasevar to the name of the database where our flattened Metriport data is - set the
input_schemavar to the name of the schema where our flattened Metriport data is (i.e.RAW_DATA) - if you've followed other dbt setup guides and your profile name is anything other than
default, you need to change theprofile:configuration to match what you've set in your profiles.yml.- Confused? Check the DBT docs: connection profiles.
You can also use this opportunity to set any normal dbt configurations you want, such as the output database or schema and any custom documentation pages, etc.
Step 4: Run
Now you're ready to execute dbt build and run the entire project.