Code Sets
Healthcare code sets are the standard terminologies that form the foundation of healthcare data. These codes classify all the important things that happens in healthcare: conditions, procedures, services, care settings, drugs, etc. Without a deep understanding of these code sets you can't effectively analyze healthcare data.
These code sets are scattered all over the internet, maintained by different organizations, and updated on different frequencies. The Tuva Project organizes and maintains these code sets so you don't have to. When you run Tuva all ~50 code sets, along with other reference datasets and value sets, are loaded directly to your data warehouse.
Below we describe these code sets in detail.
HCPCS
HCPCS stands for Healthcare Common Procedure Coding System (commonly pronounced "hick-picks"). It's used on both professional and institutional claims, however, it's used as the primary fee schedule for professional claims, so it's especially important for that claim type.
There are two levels of HCPCS codes. Level 1 is commonly referred to as CPT, or Current Procedure Terminology, and is maintained by the AMA, or American Medical Association. Level 1 is used to represent services and procedures performed by physicians or other healthcare professionals. For example, when you see your doctor in their office or in the emergency department, this is coded using a Level 1 code. All CPT codes are 5-digit numeric.
Level 2 is simply known as HCPCS Level 2 and is maintained by CMS. Level 2 codes represent services not represented by Level 1, including durable medical equipment and ambulance services. Level 2 codes are 4-digit numeric.
The Level 2 codes are included in the Tuva Project Terminology code sets. However, Level 1 is not publicly available and requires a license from the AMA to access.
There are approximately 10,000 Level 1 and 8,000 Level 2 codes. The Level 2 codes are available in the terminology.hcpcs_level_2 table.
References
NDC
NDC standards for National Drug Code. The NDC on a pharmacy claim identifies the actual drug being prescribed. The NDC code set was first introduced in 1972 by the U.S. Food and Drug Administration (FDA). Today there are well over 800,000 distinct codes in circulation. The exact number of codes isn't known because this terminology has not been well-managed over the years.
The Tuva Project gets NDC, along with RxNorm and ATC, from CodeRx. This data is pulled from the FDA and merged with a couple of other sources (because the FDA source is incomplete) and updated monthly. The NDC dictionary is available in the terminology.ndc data table.
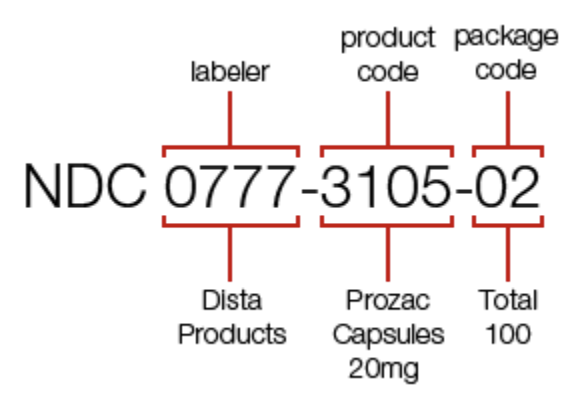
The original NDC consisted of 10 digits broken up into 3 segments:
- 1st Segment: Labeler
- 2nd Segment: Product
- 3rd Segment: Package
The Labeler segment is the only segment assigned by the FDA and it identifies the drug manufacturer i.e. the organization that produced the drug. The product segment identifies specific information about the drug. And the package segment identifies specific information about the package e.g. number of pills.
Today, NDC codes are written as a 10-digit number on drug packaging. You typically find this number near the bar code on the packaging. An additional digit is added, bringing the total to 11 digits, when billing an NDC on a healthcare claim. The 11-digit number follows a 5-4-2 format i.e. 5 digits in the first segment, 4 digits in the second segment, and 2 digits in the third segment. The rules for which segment the additional digit is added to are as follows:
- 4-4-2 becomes 5-4-2
- 5-3-2 becomes 5-4-2
- 5-4-1 becomes 5-4-2
Essentially you add a leading zero to whichever segment needs it.
Not Just NDCs
The NDC field in claims data is a complicated data element to work with, not just because of the 11-digit issue mentioned above, but also because the field contains entries from other code sets. For example, the NDC field in a claims dataset will also contain:
- NDCs that have not been fully approved by the FDA
- Drug Supply or Medical Device Codes e.g. UPC (Universal Product Code) or HRI (National Health Related Item Codes)
The latter is included because retail pharmacies often sell and bill health insurers for drug supplies and other medical equipment e.g. syringes for insulin.
One Drug, Many NDCs
Another thing that makes NDC a complex data element to work with is that there are often many NDCs for the same drug or active ingredient. So answering a question like “which patients have received Drug X?” often requires looking up dozens of NDCs. There are more than 600 distinct NDCs for acetaminophen.
Because of these complexities, if you’re doing analytics on pharmacy claims, the typical approach is to map NDC to other drug classification terminologies and use these other terminologies for analytics. In the Tuva Project we map NDCs to RxNorm codes and then map RxNorm codes to ATCs. This allows you to lookup a particular ATC code to easily ask questions like "which patients have taken a beta blocker?"
References
- The Drug Data to Knowledge Pipeline: Large-Scale Claims Data Classification for Pharmacologic Insight
- Using National Drug Codes and Drug Knowledge Bases to Organize Prescription Records from Multiple Sources
- National Drug Code (NDC) Conversion Table
- National Drug Codes Idaho MMIS
- https://www.fda.gov/drugs/drug-approvals-and-databases/national-drug-code-directory
- https://www.bcbsil.com/pdf/pharmacy/ndc_faqs.pdf
- Estimating Medication Persistency Using Administrative Claims Data
- Using Pharmacy Claims Data to Study Adherence to Glaucoma Medications: Methodology and Findings of the Glaucoma Adherence and Persistency Study (GAPS)
- Accuracy of Prescription Claims Data in Identifying Truly Nonadherent Patients